0. ref Go 语言之旅
Go web develop
Halfrost-Field/new_gopher_tips.md at master · halfrost/Halfrost-Field
topgoer · Go语言中文文档
Go sync.Cond | Go 语言高性能编程 | 极客兔兔
《Go 入门指南》 | Go 技术论坛
1. 简介 诞生
类C
2. Go安装 windows
linux
3. IDE及工具 Goland From Jetbrains
4. 包,变量和函数 Go语言的基本类型有:
bool
string
int、int8、int16、int32、int64
uint、uint8、uint16、uint32、uint64、uintptr
byte // uint8 的别名
rune // int32 的别名 代表一个 Unicode 码
float32、float64
complex64、complex128
当一个变量被声明之后,系统自动赋予它该类型的零值:int 为 0,float 为 0.0,bool 为 false,string 为空字符串,指针为 nil 等。所有的内存在 Go 中都是经过初始化的。
包 package 1 2 3 4 5 6 7 8 9 10 11 package mainimport ( "fmt" "math" ) func main () fmt.Printf("Now you have %g problems.\n" , math.Sqrt(7 )) }
导出名一个名字以大写字母开头 ,那么它就是已导出的。例如,Pizza 就是个已导出名,Pi 也同样,它导出自 math 包。
pizza 和 pi 并未以大写字母开头,所以它们是未导出的。
1 2 3 4 5 6 7 8 9 10 11 12 package mainimport ( "fmt" "math" ) func main () fmt.Println(math.Pi) }
常量、变量 := 初始化赋值
var 关键字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package main import "fmt" func main () var a, b *int fmt.Println(a, b) c := 10 b = &c fmt.Println(b) var ( a int b string c []float32 d func () bool e struct { x int } ) a:= 1 b:= 2 }
常量的声明与变量类似,只不过是使用 const 关键字。
常量可以是字符、字符串、布尔值或数值。
常量不能用 := 语法声明。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package mainimport "fmt" const Pi = 3.14 func main () const World = "世界" fmt.Println("Hello" , World) fmt.Println("Happy" , Pi, "Day" ) const Truth = true fmt.Println("Go rules?" , Truth) }
bool true false
== != && || !
数字类型
float32的精度是小数点后七位 有效数字为2^23次方 只有七位数
float64是小数点后15位
类型转换 1 2 3 4 5 6 7 8 9 10 11 12 表达式 T(v) 将值 v 转换为类型 T。 一些关于数值的转换: var i int = 42 var f float64 = float64 (i)var u uint = uint (f)或者,更加简单的形式: i := 42 f := float64 (i) u := uint (f)
类型推导 在声明一个变量而不指定其类型时(即使用不带类型的 := 语法或 var = 表达式语法),变量的类型由右值推导得出。
当右值声明了类型时,新变量的类型与其相同:
不过当右边包含未指明类型的数值常量时,新变量的类型就可能是 int, float64 或 complex128 了,这取决于常量的精度:
1 2 3 i := 42 f := 3.142 g := 0.867 + 0.5i
golang格式化输出-fmt包用法详解
复数 complex64 (32 位实数和虚数) complex128 (64 位实数和虚数)
byte
Go提供了两种大小的复数类型:complex64和complex128,分别由float32和float64组成。内置函数complex从指定的实部和虚部构建复数,内置函数real和imag用来获取复数的实部和虚部:
1 2 3 4 5 var x complex128 = complex (1 , 2 ) var y complex128 = complex (3 , 4 ) fmt.Println(x*y) fmt.Println(real (x*y)) fmt.Println(imag (x*y))
字符串 %s
strings 和 strcov包
指针 *p 取出地址中的值
&a 获得指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 var a string = "a1" func main () p := &a fmt.Printf("%p\n" , p) fmt.Printf("%s\n" , *p) fmt.Printf("%p" , &p) }
结构体 struct go语句结尾不需要分号
Go支持C语言风格的 /* */块注释,也支持C++风格的 //行注释。 当然,行注释更通用,块注释主要用于针对包的详细说明或者屏蔽大块的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 package mainimport "fmt" func main () k := 1 m := &k fmt.Println(k) fmt.Println(m) fmt.Println(*m) *m = 10 fmt.Println(m) fmt.Println(k) fmt.Println(Vertex{x: 1 ,y:2 }) fmt.Println(Vertex{1 , 2 }) v:=Vertex{10 ,23 } fmt.Println(v.x) fmt.Println(v.y) pointer := &v fmt.Println((*pointer).x) fmt.Println(pointer.x) var ( v1 = Vertex{1 , 2 } v2 = Vertex{x: 1 } v3 = Vertex{} v4 = Vertex{y: 1 } p = &Vertex{1 ,2 } ) fmt.Println(v1, p , v2, v3, v4) fmt.Println(p.x) fmt.Println(*p) } type Vertex struct { x int y int }
数组 array 类型 [n]T 表示拥有 n 个 T 类型的值的数组。
表达式: var a [10]int 会将变量 a 声明为拥有 10 个整数的数组。
数组的长度是其类型的一部分,因此数组不能改变大小。这看起来是个限制,不过没关系,Go 提供了更加便利的方式来使用数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport "fmt" func main () var a [2 ]int var b [3 ]string fmt.Println(a) fmt.Println(b) b[0 ] = "hello" b[1 ] = "world=" b[2 ] = "fuck" fmt.Println(b) c := [2 ]int {1 ,3 } fmt.Println(c) var d = [2 ]int {2 ,2 } fmt.Println(d) }
切片 slice Golang 入门 : 切片(slice) - sparkdev - 博客园
每个数组的大小都是固定的。而切片则为数组元素提供动态大小的、灵活的视角。在实践中,切片比数组更常用。
类型 []T 表示一个元素类型为 T 的切片。
切片通过两个下标来界定,即一个上界和一个下界,二者以冒号分隔:a[low : high]
它会选择一个半开区间,包括第一个元素,但排除最后一个元素。
a[1:4]表达式创建了一个切片,它包含 a 中下标从 1 到 3 的元素:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport "fmt" func main () a := [5 ]int {1 ,2 ,3 ,4 ,5 } b := a[0 :1 ] fmt.Println(b) var c = a[0 :1 ] fmt.Println(c) var d []int = a[0 :2 ] fmt.Println(d) var e []int fmt.Println(e) var f []*int fmt.Println(f) var g [2 ]*int fmt.Println(g) }
切片就像数组的引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport "fmt" func main () names := [4 ]string { "John" , "Paul" , "George" , "Ringo" , } fmt.Println(names) a := names[0 :2 ] b := names[1 :3 ] fmt.Println(a, b) b[0 ] = "XXX" fmt.Println(a, b) fmt.Println(names) }
切片文法[3]bool{true, true, false}[]bool{true, true, false}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport "fmt" func main () q := []int {2 , 3 , 5 , 7 , 11 , 13 } fmt.Println(q) r := []bool {true , false , true , true , false , true } fmt.Println(r) s := []struct { i int b bool }{ {2 , true }, {3 , false }, {5 , true }, {7 , true }, {11 , false }, {13 , true }, } fmt.Println(s) }
切片的默认行为
对于数组var a [10]int
1 2 3 4 5 a[0 :10 ] a[:10 ] a[0 :] a[:]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package mainimport "fmt" func main () s := []int {2 , 3 , 5 , 7 , 11 , 13 } s = s[1 :4 ] fmt.Println(s) s = s[:2 ] fmt.Println(s) s = s[1 :] fmt.Println(s) }
切片的长度与容量
切片的长度len就是它所包含的元素个数。
切片的容量cap是从它的第一个元素开始数,到其底层数组元素末尾的个数。
切片 s 的长度和容量可通过表达式 len(s) 和 cap(s) 来获取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport "fmt" func main () a:= [5 ]int {1 ,2 ,3 ,4 ,5 } b:= a[1 :2 ] fmt.Println(b) fmt.Println("len:" ,len (b), "cap:" , cap (b)) b = a[2 :] fmt.Println(b) fmt.Println("len:" ,len (b), "cap:" , cap (b)) }
切片的零值是 nil。
1 2 3 4 5 6 7 8 9 10 11 12 package mainimport "fmt" func main () var s []int fmt.Println(s, len (s), cap (s)) if s == nil { fmt.Println("nil!" ) } }
用 make 创建切片
切片可以用内建函数 make 来创建,这也是你创建动态数组的方式。
make 函数会分配一个元素为零值的数组并返回一个引用了它的切片:
a := make([]int, 5) // len(a)=5
要指定它的容量,需向 make 传入第三个参数:
1 2 3 4 5 b := make ([]int , 0 , 5 ) b = b[:cap (b)] b = b[1 :]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport "fmt" func main () a := make ([]int , 5 ) printSlice("a" , a) b := make ([]int , 0 , 5 ) printSlice("b" , b) c := b[:2 ] printSlice("c" , c) d := c[2 :5 ] printSlice("d" , d) } func printSlice (s string , x []int ) fmt.Printf("%s len=%d cap=%d %v\n" , s, len (x), cap (x), x) }
切片的切片。和二维数组差不多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package mainimport ( "fmt" "strings" ) func main () board := [][]string { []string {"_" , "_" , "_" }, []string {"_" , "_" , "_" }, []string {"_" , "_" , "_" }, } board[0 ][0 ] = "X" board[2 ][2 ] = "O" board[1 ][2 ] = "X" board[1 ][0 ] = "O" board[0 ][2 ] = "X" for i := 0 ; i < len (board); i++ { fmt.Printf("%s\n" , strings.Join(board[i], " " )) } }
向切片追加元素
func append(s []T, vs ...T) []T
当 s 的底层数组太小,不足以容纳所有给定的值时,它就会分配一个更大的数组。返回的切片会指向这个新分配的数组。
Go 切片:用法和本质 - Go 语言博客
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport "golang.org/x/tour/pic" func Pic (dx, dy int ) uint8 { a := make ([][]uint8 , dy) for x:= range a{ b := make ([]uint8 , dx) for y:= range b{ b[y] = uint8 (x^y) } a[x] = b } return a } func main () pic.Show(Pic) }
Range for 循环的 range 形式可遍历切片或映射。
当使用 for 循环遍历切片时,每次迭代都会返回两个值。第一个值为当前元素的下标,第二个值为该下标所对应元素的一份副本。
可以将下标或值赋予 _ 来忽略它。
1 2 3 4 5 6 for i, _ := range powfor _, value := range powfor i := range pow
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package mainimport "fmt" import "reflect" func main () a := []int {1 , 2 , 3 , 4 , 5 } for i, v := range a { fmt.Printf("%d : %d \n" , i, v) } for i, _ := range a { fmt.Printf("%d \n" , i) } fmt.Println("-------------" ) b := []int {1 } for i, v := range b { fmt.Println(reflect.TypeOf(v)) p1 := &v; p2 := &a[i] fmt.Println(p1) fmt.Println(p2) fmt.Println(p1 == p2) fmt.Printf("%d \n" , v) } }
Map 零值为 nil 。nil 映射既没有键,也不能添加键。make 函数会返回给定类型的映射,并将其初始化备用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport "fmt" type Vertex struct { Lat, Long float64 } var m map [string ]Vertexfunc main () m = make (map [string ]Vertex) m["Bell Labs" ] = Vertex{ 40.68433 , -74.39967 , } fmt.Println(m["Bell Labs" ]) }
map的文法与结构体相似,不过必须有键名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package mainimport "fmt" type Vertex struct { Lat, Long float64 } var m = map [string ]Vertex{ "Bell Labs" : Vertex{ 40.68433 , -74.39967 , }, "Google" : Vertex{ 37.42202 , -122.08408 , }, } func main () fmt.Println(m) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package mainimport "fmt" type Vertex struct { Lat, Long float64 } var m = map [string ]Vertex{ "Bell Labs" : {40.68433 , -74.39967 }, "Google" : {37.42202 , -122.08408 }, } func main () fmt.Println(m) }
多赋值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport "fmt" func main () var m1 map [int ]int m1 = map [int ]int {1 :1 } fmt.Println(m1) m2 := map [string ]int { "a" : 1 , "b" : 2 , } fmt.Println(m2) m2["a" ] = 3 fmt.Println(m2) fmt.Println(m2["a" ]) delete (m2,"a" ) fmt.Println(m2) elem, ok := m2["a" ] fmt.Println(elem) fmt.Println(ok) m3:= map [int ]string { 1 :"a" , 2 :"b" , } elem1, ok1 := m3[3 ] fmt.Println(elem1) fmt.Println(ok1) }
练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package mainimport ( "golang.org/x/tour/wc" "strings" ) func WordCount (s string ) map [string ]int { var m = make (map [string ]int ) strs := strings.Fields(s) for _, v := range strs{ if elem, ok:= m[v]; ok { elem++ m[v] = elem }else { m[v] = 1 } } return m } func main () wc.Test(WordCount) }
func Fields(s string) []stringan array of substrings of s or an empty list if s contains only white space.
func Split(s, sep string) []stringSplit slices s into all substrings separated by sep and returns a slice of the substrings between those separators. If sep is empty, Split splits after each UTF-8 sequence. It is equivalent to SplitN with a count of -1.
1 2 3 4 5 6 7 8 9 10 11 fmt.Printf("%q\n" , strings.Split("a,b,c" , "," )) fmt.Printf("%q\n" , strings.Split("a man a plan a canal panama" , "a " )) fmt.Printf("%q\n" , strings.Split(" xyz " , "" )) fmt.Printf("%q\n" , strings.Split("" , "Bernardo O'Higgins" ))
函数 function 函数可以将其他函数调用作为它的参数,只要这个被调用函数的返回值个数、返回值类型和返回值的顺序与调用函数所需求的实参是一致的,例如:
假设 f1 需要 3 个参数 f1(a, b, c int),同时 f2 返回 3 个参数 f2(a, b int) (int, int, int),就可以这样调用 f1:f1(f2(a, b))。
Go不允许函数重载 ,Go 语言不支持这项特性的主要原因是函数重载需要进行多余的类型匹配影响性能;没有重载意味着只是一个简单的函数调度。所以你需要给不同的函数使用不同的名字,我们通常会根据函数的特征对函数进行命名
type binOp func(int, int) int 定义函数类型
声明 1 2 3 4 5 6 7 8 9 10 11 12 13 package mainimport "fmt" func add (x, y int ) int { return x + y } func main () fmt.Println(add(42 , 13 )) }
函数也是值。它们可以像其它值一样传递。
函数值可以用作函数的参数或返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport ( "fmt" "math" ) func compute (f1 func (float64 , float64 ) float64 , x, y float64 ) float64 { return f1(x,y) } func main () hypot := func (x, y float64 ) float64 { return math.Sqrt(x*x + y*y) } fmt.Println(compute(hypot, 3 , 4 )) fmt.Println(compute(math.Pow, 2 , 3 )) }
闭包 closure Go 函数可以是一个闭包。闭包是一个函数值,它引用了其函数体之外的变量。该函数可以访问并赋予其引用的变量的值,换句话说,该函数被这些变量“绑定”在一起。
例如,函数 adder 返回一个闭包。每个闭包都被绑定在其各自的 sum 变量上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport "fmt" func adder () func (int ) int { sum := 0 return func (x int ) int { sum += x return sum } } func main () pos, neg := adder(), adder() for i := 0 ; i < 10 ; i++ { fmt.Println( pos(i), neg(-2 *i), ) } }
闭包练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport "fmt" func fibonacci () func () int { pre1:= 0 pre2:= 1 return func () int { tmp:= pre1 pre1,pre2 = pre2, (pre1 + pre2) return tmp } } func main () f := fibonacci() for i := 0 ; i < 10 ; i++ { fmt.Println(f()) } }
内置函数 Go 语言拥有一些不需要进行导入操作就可以使用的内置函数。它们有时可以针对不同的类型进行操作,例如:len、cap 和 append,或必须用于系统级的操作,例如:panic。因此,它们需要直接获得编译器的支持。
以下是一个简单的列表,我们会在后面的章节中对它们进行逐个深入的讲解。
名称
说明
close
用于管道通信
len、cap
len 用于返回某个类型的长度或数量(字符串、数组、切片、map 和管道);cap 是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
new、make
用来分配内存,返回Type本身(只能应用于slice, map, channel)<br>用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
copy、append
用于复制和连接切片
panic、recover
两者均用于错误处理机制
print、println
底层打印函数(详见第 4.2 节),在部署环境中建议使用 fmt 包
complex、real、imag
用于创建和操作复数(详见第 4.5.2.2 节)
日期时间 运算符 位运算
算术运算符
++ —只能用于后缀
逻辑运算符
优先级 运算符
fmt print 1 2 3 4 5 6 7 8 9 10 Print: 输出到控制台(不接受任何格式化,它等价于对每一个操作数都应用 %v) fmt.Print(str) Println: 输出到控制台并换行 fmt.Println(tmp) Printf : 只可以打印出格式化的字符串。只可以直接输出字符串类型的变量 fmt.Printf("%d",a) Sprintf:格式化并返回一个字符串而不带任何输出。 s := fmt.Sprintf("a %s", "string") fmt.Printf(s) Fprintf:来格式化并输出到 io.Writers 而不是 os.Stdout。 fmt.Fprintf(os.Stderr, “an %s\n”, “error”)
Go语言fmt.Printf使用指南(占位符总结)格式化打印 加精!!!_youngsailor的博客-CSDN博客
1 2 3 4 5 6 7 8 %v: 以默认的方式打印变量的值(万能占位符,如果不知道变量是什么类型,用%v即可,go语言会自动为你识别) %+d 带符号的整型 %d 正号不带。负数还是会带 %q 打印单引号 %q 字符串带双引号,字符串中的引号带转义符
named return 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport "fmt" func split (sum int ) int ) { x = sum * 4 / 9 y = sum - x return } func main () fmt.Println(split(17 )) } func split (sum int ) int ) { x = 1 y = 2 y = 3 z = 4 return } func main () fmt.Println(split(17 )) }
相当于在函数一开始就申明了变量x y。 return空的时候,就会返回声明的值
Go’s return values may be named. If so, they are treated as variables defined at the top of the function.
These names should be used to document the meaning of the return values.
A return statement without arguments returns the named return values. This is known as a “naked” return.
Naked return statements should be used only in short functions, as with the example shown here. They can harm readability in longer functions.
5. 控制结构 if else 1 2 3 4 5 6 7 if condition1 { } else if condition2 { } else { }
关键字 if 和 else 之后的左大括号 { 必须和关键字在同一行,如果你使用了 else-if 结构,则前段代码块的右大括号 } 必须和 else-if 关键字在同一行。这两条规则都是被编译器强制规定的。
多返回值 1 2 3 4 5 6 7 8 if err := file.Chmod(0664 ); err != nil { fmt.Println(err) return err } if value, ok := readData(); ok {… }
在if语句中进行初始化
使用_丢弃返回值
1 2 3 4 5 6 7 8 9 func mySqrt (f float64 ) float64 , ok bool ) { if f < 0 { return } return math.Sqrt(f),true } func main () t := mySqrt(25.0 ) fmt.Println(t) }
switch case 不过 Go 只运行选定的 case,而非之后所有的 case。 实际上,Go 自动提供了在这些语言中每个 case 后面所需的 break 语句。 除非以 fallthrough 语句结束,否则分支会自动终止。 Go 的另一点重要的不同在于 switch 的 case 无需为常量,且取值不必为整数。
1 2 3 4 5 6 7 8 switch var1 { case val1: ... case val2: ... default : ... }
fall through
1 2 3 4 5 switch i { case 0 : fallthrough case 1 : f() }
替换if else
1 2 3 4 5 6 7 8 switch { case i < 0 : f1() case i == 0 : f2() case i > 0 : f3() }
for 如果想要重复执行某些语句,Go 语言中您只有 for 结构可以使用。没有while
普通for 和java一样 除了没有()
1 2 3 4 5 6 7 8 9 package mainimport "fmt" func main () for i := 0 ; i < 5 ; i++ { fmt.Printf("This is the %d iteration\n" , i) } }
类似while 1 2 3 4 5 6 7 8 9 10 11 12 package mainimport "fmt" func main () var i int = 5 for i >= 0 { i = i - 1 fmt.Printf("The variable i is now: %d\n" , i) } }
无限循环 条件语句是可以被省略的,如 i:=0; ; i++ 或 for { } 或 for ;; { }(;; 会在使用 gofmt 时被移除):这些循环的本质就是无限循环。最后一个形式也可以被改写为 for true { },但一般情况下都会直接写 for { }
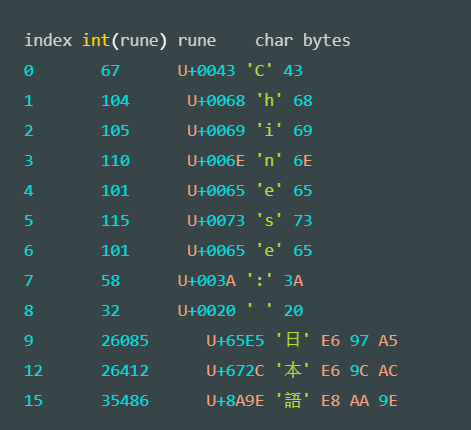
for range 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package mainimport "fmt" func main () str := "Go is a beautiful language!" fmt.Printf("The length of str is: %d\n" , len (str)) for pos, char := range str { fmt.Printf("Character on position %d is: %c \n" , pos, char) } fmt.Println() str2 := "Chinese: 日本語" fmt.Printf("The length of str2 is: %d\n" , len (str2)) for pos, char := range str2 { fmt.Printf("character %c starts at byte position %d\n" , char, pos) } fmt.Println() fmt.Println("index int(rune) rune char bytes" ) for index, rune := range str2 { fmt.Printf("%-2d %d %U '%c' % X\n" , index, rune , rune , rune , []byte (string (rune ))) } }
break continue 嵌套的循环体,break 只会退出最内层的循环
标签 goto 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package mainimport "fmt" func main () LABEL1: for i := 0 ; i <= 5 ; i++ { for j := 0 ; j <= 5 ; j++ { if j == 4 { continue LABEL1 } fmt.Printf("i is: %d, and j is: %d\n" , i, j) } } }
1 2 3 4 5 6 7 8 9 10 11 package mainfunc main () i:=0 HERE: print (i) i++ if i==5 { return } goto HERE
goto is not encouraged
defer 推迟的函数调用会被压入一个栈中。当外层函数返回时,被推迟的函数会按照后进先出的顺序调用。
推迟调用的函数其参数会立即求值,但直到外层函数返回前该函数都不会被调用。
1 2 3 4 5 6 7 8 9 10 11 package mainimport "fmt" func main () defer fmt.Println("world" ) fmt.Println("hello" ) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package mainimport "fmt" func main () fmt.Println("counting" ) for i := 0 ; i < 10 ; i++ { defer fmt.Println(i) } fmt.Println("done" ) }
6. 方法和接口 方法 Go 没有类。不过你可以为结构体类型定义方法。
方法就是一类带特殊的 接收者 (receiver)参数的函数。
方法的接收者在它自己的参数列表内,位于 func 关键字和方法名之间。
在此例中,Abs 方法拥有一个名为 v,类型为 Vertex 的接收者。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport ( "fmt" "math" ) type Vertex struct { X, Y float64 } func (v Vertex) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) } func main () v := Vertex{3 , 4 } fmt.Println(v.Abs()) v2:= Vertex{1 ,2 } fmt.Println(v2.Abs()) }
普通的函数 func funcName(arg1, arg2 argType) (returnType)
方法 vs 函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func (v Vertex) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) } func main () v := Vertex{3 , 4 } fmt.Println(v.Abs()) } func Abs (v Vertex) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) } func main () v := Vertex{3 , 4 } fmt.Println(Abs(v)) }
也可以为非结构体类型声明方法。
在此例中,我们看到了一个带 Abs 方法的数值类型 MyFloat。
接收者的类型定义和方法声明必须在同一包内;不能为内建类型(因为type是其他包内定义的类型)声明方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package mainimport ( "fmt" "math" ) type MyFloat float64 func (f MyFloat) float64 { if f < 0 { return float64 (-f) } return float64 (f) } func main () fmt.Println(math.Sqrt2) f := MyFloat(-math.Sqrt2) fmt.Println(f.Abs()) }
指针 vs 值 接收者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package mainimport ( "fmt" "math" ) type Vertex struct { X, Y float64 } func (v Vertex) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) } func (v *Vertex) float64 ) { v.X = v.X * f v.Y = v.Y * f } func (v Vertex) float64 ) { v.X = v.X * f v.Y = v.Y * f } func main () v1 := Vertex{3 , 4 } v2 := Vertex{3 , 4 } v1.Scale1(10 ) v2.Scale2(10 ) fmt.Println(v1.Abs()) fmt.Println(v2.Abs()) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package mainimport ( "fmt" "math" ) type Vertex struct { X, Y float64 } func Abs (v Vertex) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) } func Scale (v *Vertex, f float64 ) v.X = v.X * f v.Y = v.Y * f } func main () v := Vertex{3 , 4 } Scale(&v, 10 ) fmt.Println(Abs(v)) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport "fmt" type Vertex struct { X, Y float64 } func (v *Vertex) float64 ) { v.X = v.X * f v.Y = v.Y * f } func ScaleFunc (v *Vertex, f float64 ) v.X = v.X * f v.Y = v.Y * f } func main () v := Vertex{3 , 4 } v.Scale(2 ) ScaleFunc(&v, 10 ) p := &Vertex{4 , 3 } p.Scale(3 ) ScaleFunc(p, 8 ) fmt.Println(v, p) }
同样的事情也发生在相反的方向。
接受一个值作为参数的函数必须接受一个指定类型的值:
1 2 3 var v Vertexfmt.Println(AbsFunc(v)) fmt.Println(AbsFunc(&v))
而以值为接收者的方法被调用时,接收者既能为值又能为指针:
1 2 3 4 var v Vertexfmt.Println(v.Abs()) p := &v fmt.Println(p.Abs())
这种情况下,方法调用 p.Abs() 会被解释为 (*p).Abs()。 p是指针。 会自动转成值
方法二者才都可以
- 接收者是值。可以传入值或者指针
- 接收者是指针。可以传入值或者指针
函数则必须匹配。
- 声明的参数类型是值就传入值。是指针就传入指针
使用指针接收者的原因有二:
首先,方法能够修改其接收者指向的值。
在本例中,Scale 和 Abs 接收者的类型为 *Vertex,即便 Abs 并不需要修改其接收者。
通常来说,所有给定类型的方法都应该有值或指针接收者,但并不应该二者混用。
接口 接口类型 是由一组方法签名定义的集合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package mainimport ( "fmt" "math" ) type Abser interface { Abs() float64 } type MyFloat float64 func main () var a Abser f := MyFloat(-math.Sqrt2) v := Vertex{3 , 4 } a = f a = &v fmt.Println(a.Abs()) } func (f MyFloat) float64 { if f < 0 { return float64 (-f) } return float64 (f) } type Vertex struct { X, Y float64 } func (v *Vertex) float64 { return math.Sqrt(v.X*v.X + v.Y*v.Y) }
类型通过实现一个接口的所有方法来实现该接口。既然无需专门显式声明,也就没有“implements”关键字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport "fmt" type I interface { M() } type T struct { S string } func (t T) fmt.Println(t.S) } func main () var i I i = T{"hello" } i.M() }
interface value
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ( "fmt" "math" ) type I interface { M() } type T struct { S string } func (t *T) fmt.Println(t.S) } type F float64 func (f F) fmt.Println(f) } func main () var i I i = &T{"Hello" } describe(i) i.M() i = F(math.Pi) describe(i) i.M() } func describe (i I) fmt.Printf("(%v, %T)\n" , i, i) }
nil 底层值为nil
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package mainimport "fmt" type I interface { M() } type T struct { S string } func (t *T) if t == nil { fmt.Println("<nil>" ) return } fmt.Println(t.S) } func main () var i I var t *T i = t describe(i) i.M() i = &T{"hello" } describe(i) i.M() } func describe (i I) fmt.Printf("(%v, %T)\n" , i, i) }
接口自身为nil
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport "fmt" type I interface { M() } func main () var i I describe(i) i.M() } func describe (i I) fmt.Printf("(%v, %T)\n" , i, i) }
空接口 指定了零个方法的接口值被称为 空接口 :interface{}
空接口可保存任何类型的值。(因为每个类型都至少实现了零个方法。)
空接口被用来处理未知类型的值。例如,fmt.Print 可接受类型为 interface{} 的任意数量的参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport "fmt" func main () var i interface {} describe(i) i = 42 describe(i) i = "hello" describe(i) } func describe (i interface {}) fmt.Printf("(%v, %T)\n" , i, i) }
类型断言 类型断言 提供了访问接口值底层具体值的方式。t := i.(T)i 保存了具体类型 T,并将其底层类型为 T 的值赋予变量 t。
若 i 并未保存 T 类型的值,该语句就会触发一个恐慌。判断 一个接口值是否保存了一个特定的类型,类型断言可返回两个值:其底层值以及一个报告断言是否成功的布尔值。t, ok := i.(T)
若 i 保存了一个 T,那么 t 将会是其底层值,而 ok 为 true。ok 将为 false 而 t 将为 T 类型的零值,程序并不会产生恐慌。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport "fmt" func main () var i interface {} = "hello" s := i.(string ) fmt.Println(s) s, ok := i.(string ) fmt.Println(s, ok) f, ok := i.(float64 ) fmt.Println(f, ok) f = i.(float64 ) fmt.Println(f) }
类型选择 类型选择 是一种按顺序从几个类型断言中选择分支的结构。
类型选择与一般的 switch 语句相似,不过类型选择中的 case 为类型(而非值), 它们针对给定接口值所存储的值的类型进行比较。
1 2 3 4 5 6 7 8 switch v := i.(type ) {case T: case S: default : }
类型选择中的声明与类型断言 i.(T) 的语法相同,只是具体类型 T 被替换成了关键字 type。
此选择语句判断接口值 i 保存的值类型是 T 还是 S。在 T 或 S 的情况下,变量 v 会分别按 T 或 S 类型保存 i 拥有的值。在默认(即没有匹配)的情况下,变量 v 与 i 的接口类型和值相同。
相当于type的switch case
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport "fmt" func do (i interface {}) switch v := i.(type ) { case int : fmt.Printf("Twice %v is %v\n" , v, v*2 ) case string : fmt.Printf("%q is %v bytes long\n" , v, len (v)) default : fmt.Printf("I don't know about type %T!\n" , v) } } func main () do(21 ) do("hello" ) do(true ) }
Stringer接口 fmtStringer
1 2 3 type Stringer interface { String() string }
Stringer 是一个可以用字符串描述自己的类型。fmt 包(还有很多包)都通过此接口来打印值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport "fmt" type Person struct { Name string Age int } func (p Person) string { return fmt.Sprintf("%v (%v years)" , p.Name, p.Age) } func main () a := Person{"Arthur Dent" , 42 } z := Person{"Zaphod Beeblebrox" , 9001 } fmt.Println(a) fmt.Println(z) }
练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport "fmt" type IPAddr [4 ]byte func (ipAddr IPAddr) string { return fmt.Sprintf("%d.%d.%d.%d" , ipAddr[0 ],ipAddr[1 ],ipAddr[2 ],ipAddr[3 ]) } func main () hosts := map [string ]IPAddr{ "loopback" : {127 , 0 , 0 , 1 }, "googleDNS" : {8 , 8 , 8 , 8 }, } for name, ip := range hosts { fmt.Printf("%v: %v\n" , name, ip) } }
error接口 错误处理
Go 程序使用 error 值来表示错误状态。
与 fmt.Stringer 类似,error 类型是一个内建接口:
1 2 3 type error interface { Error() string }
(与 fmt.Stringer 类似,fmt 包在打印值时也会满足 error。)
通常函数会返回一个 error 值,调用的它的代码应当判断这个错误是否等于 nil 来进行错误处理。
1 2 3 4 5 6 i, err := strconv.Atoi("42" ) if err != nil { fmt.Printf("couldn't convert number: %v\n" , err) return } fmt.Println("Converted integer:" , i)
error 为 nil 时表示成功;非 nil 的 error 表示失败。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport ( "fmt" "time" ) type MyError struct { When time.Time What string } func (e *MyError) string { return fmt.Sprintf("at %v, %s" , e.When, e.What) } func run () error { return &MyError{ time.Now(), "it didn't work" , } } func main () if err := run(); err != nil { fmt.Println(err) } }
Reader 7. 并发 goroutine goroutine 是由 Go 运行时管理的轻量级线程。
go f(x, y, z)
会启动一个新的 Go 程并执行
f(x, y, z)
f, x, y 和 z 的求值发生在当前的 Go 程中,而 f 的执行发生在新的 Go 程中。
goroutine在相同的地址空间中运行 ,因此在访问共享的内存时必须进行同步。sync
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport ( "fmt" "time" ) func say (s string ) for i := 0 ; i < 5 ; i++ { time.Sleep(1000 * time.Millisecond) fmt.Println(s) } } func main () go say("world" ) say("hello" ) }
channel 信道是带有类型的管道,你可以通过它用信道操作符 <- 来发送或者接收值。
ch <- v // 将 v 发送至信道 ch。
(“箭头”就是数据流的方向。)
和映射与切片一样,信道在使用前必须创建:
ch := make(chan int)
默认情况下,发送和接收操作在另一端准备好之前都会阻塞。这使得 Go 程可以在没有显式的锁或竞态变量的情况下进行同步。
以下示例对切片中的数进行求和,将任务分配给两个 Go 程。一旦两个 Go 程完成了它们的计算,它就能算出最终的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport "fmt" func sum (s []int , c chan int ) sum := 0 for _, v := range s { sum += v } c <- sum } func main () s := []int {7 , 2 , 8 , -9 , 4 , 0 } c := make (chan int ) go sum(s[:len (s)/2 ], c) go sum(s[len (s)/2 :], c) x, y := <-c, <-c fmt.Println(x, y, x+y) }
带缓冲的信道
信道可以是 带缓冲的 。将缓冲长度作为第二个参数提供给 make 来初始化一个带缓冲的信道:
ch := make(chan int, 100)
仅当信道的缓冲区填满后,向其发送数据时才会阻塞。当缓冲区为空时,接受方会阻塞。
修改示例填满缓冲区,然后看看会发生什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport "fmt" func main () ch := make (chan int , 3 ) ch <- 1 ch <- 2 ch <- 3 fmt.Println(<-ch) fmt.Println(<-ch) fmt.Println(<-ch) }
range 和 close
发送者可通过 close 关闭一个信道来表示没有需要发送的值了。接收者可以通过为接收表达式分配第二个参数来测试信道是否被关闭:若没有值可以接收且信道已被关闭,那么在执行完
v, ok := <-ch
之后 ok 会被设置为 false。
循环 for i := range c 会不断从信道接收值,直到它被关闭。
注意: 只有发送者才能关闭信道,而接收者不能。向一个已经关闭的信道发送数据会引发程序恐慌(panic)。
还要注意: 信道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收者不再有需要发送的值时才有必要关闭,例如终止一个 range 循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package mainimport ( "fmt" ) func fibonacci (n int , c chan int ) x, y := 0 , 1 for i := 0 ; i < n; i++ { c <- x x, y = y, x+y } close (c) } func main () c := make (chan int , 10 ) go fibonacci(cap (c), c) for i := range c { fmt.Println(i) } }
select 语句
select 语句使一个 Go 程可以等待多个通信操作。
select 会阻塞到某个分支可以继续执行为止,这时就会执行该分支。当多个分支都准备好时会随机选择一个执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package mainimport "fmt" func fibonacci (c, quit chan int ) x, y := 0 , 1 for { select { case c <- x: x, y = y, x+y case <-quit: fmt.Println("quit" ) return } } } func main () c := make (chan int ) quit := make (chan int ) go func () for i := 0 ; i < 10 ; i++ { fmt.Println(<-c) } quit <- 0 }() fibonacci(c, quit) }
当 select 中的其它分支都没有准备好时,default 分支就会执行。
为了在尝试发送或者接收时不发生阻塞,可使用 default 分支:
1 2 3 4 5 6 select {case i := <-c: default : }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport ( "fmt" "time" ) func main () tick := time.Tick(100 * time.Millisecond) boom := time.After(500 * time.Millisecond) for { select { case <-tick: fmt.Println("tick." ) case <-boom: fmt.Println("BOOM!" ) return default : fmt.Println(" ." ) time.Sleep(50 * time.Millisecond) } } }
sync.Mutex 我们已经看到信道非常适合在各个 Go 程间进行通信。
但是如果我们并不需要通信呢?比如说,若我们只是想保证每次只有一个 Go 程能够访问一个共享的变量,从而避免冲突?
这里涉及的概念叫做 互斥(mutual exclusion) ,我们通常使用 互斥锁(Mutex)* 这一数据结构来提供这种机制。
Go 标准库中提供了 sync.Mutex
我们可以通过在代码前调用 Lock 方法,在代码后调用 Unlock 方法来保证一段代码的互斥执行。参见 Inc 方法。
我们也可以用 defer 语句来保证互斥锁一定会被解锁。参见 Value 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package mainimport ( "fmt" "sync" "time" ) type SafeCounter struct { v map [string ]int mux sync.Mutex } func (c *SafeCounter) string ) { c.mux.Lock() c.v[key]++ c.mux.Unlock() } func (c *SafeCounter) string ) int { c.mux.Lock() defer c.mux.Unlock() return c.v[key] } func main () c := SafeCounter{v: make (map [string ]int )} for i := 0 ; i < 1000 ; i++ { go c.Inc("somekey" ) } time.Sleep(time.Second) fmt.Println(c.Value("somekey" )) }
WaitGroup sync.WaitGroup 详解
main 协程通过调用 wg.Add(delta int) 设置 worker 协程的个数,然后创建 worker 协程;
worker 协程执行结束以后,都要调用 wg.Done();
main 协程调用 wg.Wait() 且被 block,直到所有 worker 协程全部执行结束后返回。